
Uncle Bob’s recent post A Little Architecture explains what the Dependency Inversion Principle is. It shows why it is the foundation for a clean application architecture.
The Dependency Inversion Principle is the most important software design principle. If you aren’t into reading programming literature, you should at least understand this one by reading this post. It’ll guide all your future application architecture design decisions.
Uncle Bob’s code examples are written in Java. But in this post, I’ll explain the Dependency Inversion Principle in terms of Swift.
If your app is properly architected, even though Parse is shutting down, it’ll be easy to replace it with whatever you want. I’ll show you why and how.
In addition to just showing the Swift code, you’ll also learn:
- What is the Dependency Inversion Principle?
- Why is it important?
- What makes it possible?
- What benefits does it provide?
The code
Let’s start with some code.
A couple notes on the differences between Java and Swift:
- Java’s
packageandimportare automatically handled by the Swift compiler. So we don’t need to worry about them, which is nice! - Java’s
publicis equivalent to Swift’sinternal. Swift functions are internal by default, so we can omit theinternalkeyword. (Side note: Swift’spublicis for exposing an API if you’re building a framework.)
Sender.swift
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
protocol Receiver { func receiveThis() } class Sender { private var receiver: Receiver init(r: Receiver) { receiver = r } func doSomething() { receiver.receiveThis() } } |
First, it defines a Receiver protocol with one method named receiveThis().
It also defines a Sender class. Inside the class, the receiver variable, of type Receiver, is made private. This means it is for internal use only within the Sender class. Users of instances of the Sender class cannot use receiver directly.
The initializer accepts a Receiver. Upon initialization, it sets the private receiver to the Receiver being passed in. This technique is called constructor dependency injection. We’ll look at dependency injection in a separate post and see how it is central to unit testing.
The doSomething() instance method implements some business logic. It simply invokes the receiveThis() method on the receiver.
Side note: Uncle Bob’s Java version has the Receiver protocol defined inside the Sender class. He wants to make explicit the fact that the higher level module should be the one to define the interface it requires from the lower level to implement.
But defining a protocol inside a class is not possible in Swift. So we’ll just have to make do with defining it outside. In fact, this actually provides an additional benefit, as you’ll see later.
SpecificReceiver.swift
|
1 2 3 4 5 6 7 8 |
class SpecificReceiver: Receiver { func receiveThis() { // do something interesting. } } |
The SpecificReceiver class conforms to the Receiver protocol. To satisfy this conformance, it implements the receiveThis() method.
What is the Dependency Inversion Principle?
The Dependency Inversion Principle Wikipedia entry defines:
In object-oriented programming, the Dependency Inversion Principle refers to a specific form of decoupling software modules. When following this principle, the conventional dependency relationships established from high-level, policy-setting modules to low-level, dependency modules are reversed, thus rendering high-level modules independent of the low-level module implementation details.
In the Sender-Receiver example, the Sender class is the high level module. The SpecificReceiver class is the low level module.
In traditional dependency, the Sender class would define a variable of type SpecificReceiver, and invoke its method like receiver.receiveThis().
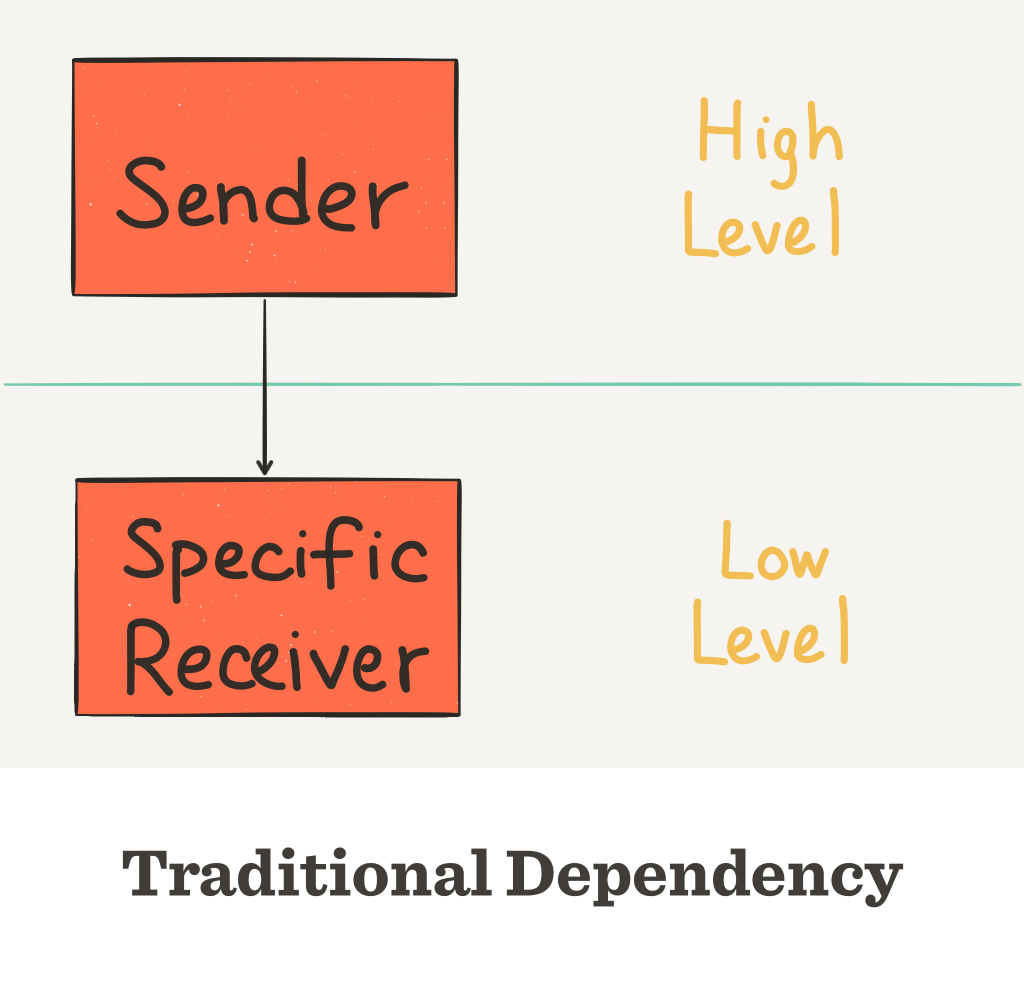
When you invert the dependency and define a Receiver interface inside the Sender class as in Uncle Bob’s example code, the direction of the arrow is flipped. The Sender no longer depends on SpecificReceiver. Rather, the SpecificReceiver depends on Sender. So the dependence is inverted.
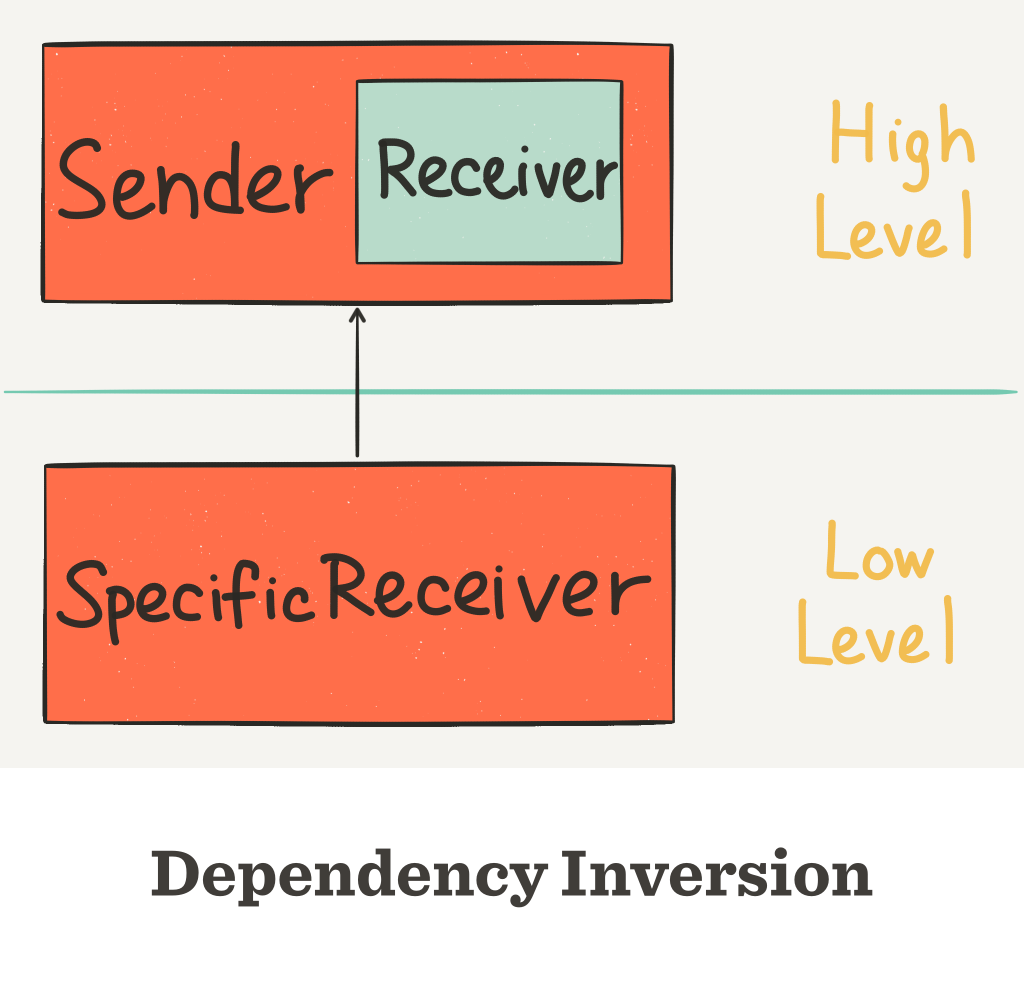
You can swap out SpecificReceiver and swap in AnotherSpecificReceiver anytime, as long as they both conform to the Receiver interface. The high level business logic in Sender can be reused.
However, it’s not possible to define a protocol inside a class in Swift. So you have to define the Receiver protocol outside of the Sender class. This is actually an improvement, because both Sender and SpecificReceiver now depend on the Receiver protocol.
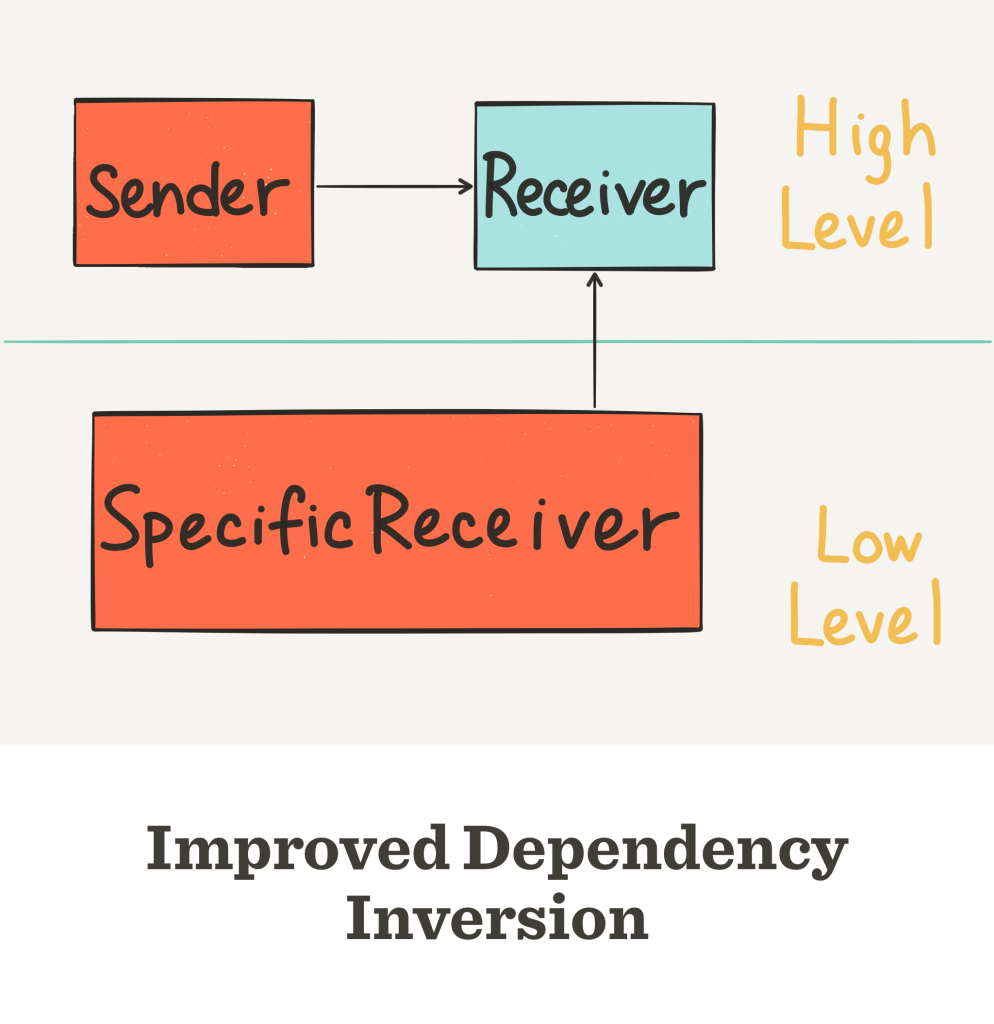
In this improved version, not only is the SpecificReceiver swappable, you can also reuse SpecificReceiver in a totally different app with different business logic. Both the high level Sender and low level SpecificReceiver can be reused.
Why is the Dependency Inversion Principle important?
Without dependency inversion and the Receiver protocol, you would have the following:
|
1 2 3 4 5 6 7 8 9 10 |
class Sender { private var receiver: SpecificReceiver func doSomething() { receiver.receiveThis() } } |
The receiver variable is of a concrete type SpecificReceiver, and you invoke its receiveThis() method directly. This means the high level Sender depends on the low level SpecificReceiver.
Why is this bad? Because if you were to change the SpecificReceiver, you would have to change the Sender as well.
Imagine if you replace SpecificReceiver with ParseService, and receiveThis() with fetchUserWithID(_:completionHandler).
|
1 2 3 4 5 6 7 8 |
class ParseService { func fetchUserWithID(id: String, completionHandler: (user: PFObject?, error: ErrorType?) -> ()) { // Do the fetch and invoke completionHandler when you get a response from Parse } } |
And your doSomething() method now looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class Sender { private var service: ParseService func doSomething() { service.fetchUserWithID("asdf") { (user: PFObject?, error: ErrorType?) in // Do something with the user } } } |
The Sender class directly depends on ParseService. This is a traditional dependency.
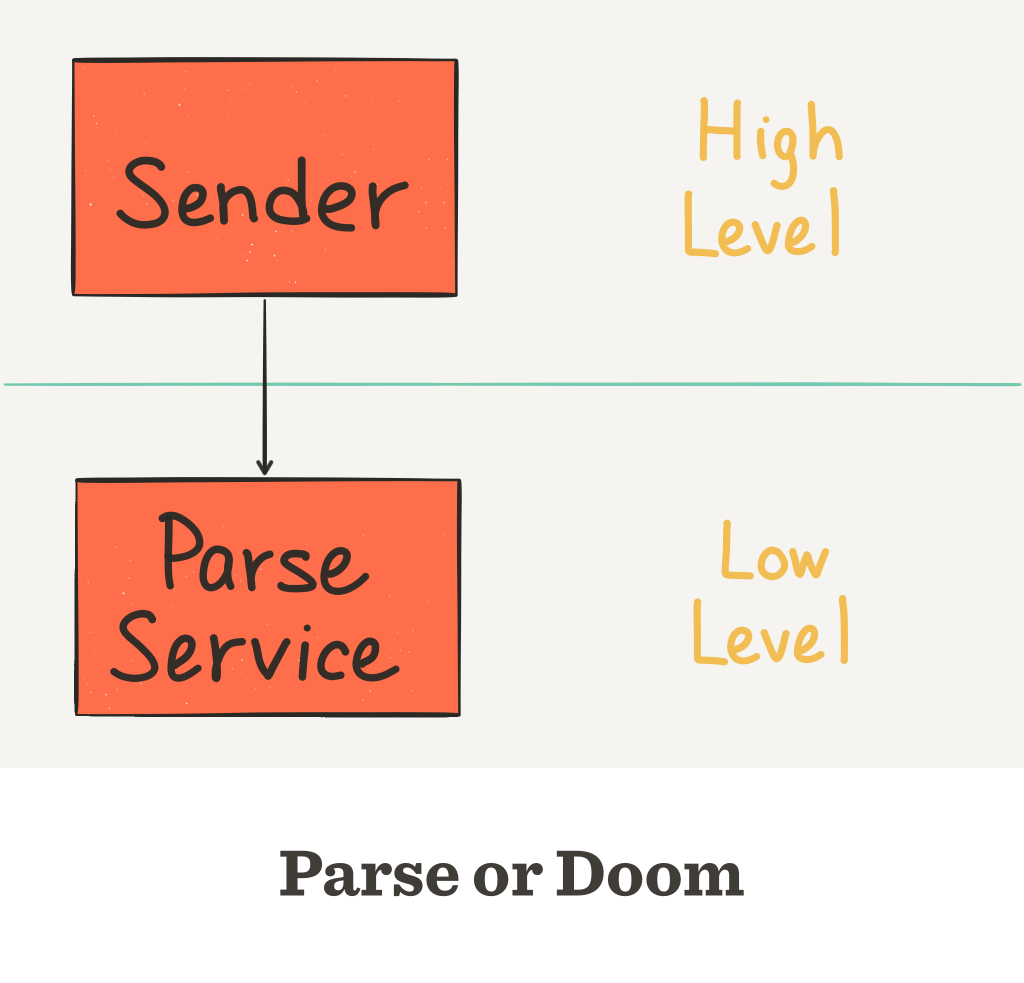
If you switch to Firebase or your own backend or what not, it may need something other than an id string to identify a user. Even if it does, PFObject only makes sense for Parse.
Now that Parse is shutting down, you would have to change everywhere you use ParseService. If you propagate PFObject further than Sender, you have to change everywhere you reference PFObject.
That’s not fun!
The Wikipedia entry goes further on and states:
A. High-level modules should not depend on low-level modules. Both should depend on abstractions.
B. Abstractions should not depend on details. Details should depend on abstractions.
Let’s design this properly with an abstraction using the Dependency Inversion Principle to see how we can avoid having to make changes throughout the code base even if Parse is shutting down.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
protocol Service { func fetchUserWithID(id: String, completionHandler: (user: User?, error: ErrorType?) -> ()) } class Sender { private var service: Service init(s: Service) { service = s } func doSomething() { service.fetchUserWithID("asdf") { (user: User?, error: ErrorType?) in // Do something with the user } } } |
We introduce a Service protocol to define the fetchUserWithID(_:completionHandler) method. Note that in the completion handler, user is of type User, not PFObject.
A specific implementation of a service could be a ParseService as follows.
|
1 2 3 4 5 6 7 8 9 10 |
class ParseService: Service { func fetchUserWithID(id: String, completionHandler: (user: User?, error: ErrorType?) -> ()) { // Do the fetch // Map PFObject into User // Ivoke completionHandler } } |
But it could also be FirebaseService or MyBackend, as long as they conform to the Service protocol and implement the fetchUserWithID(_:completionHandler) method.
This is the improved dependency inversion, as shown in the following diagram. Any service or backend just needs to conform to the Service protocol in order to be used by Sender.
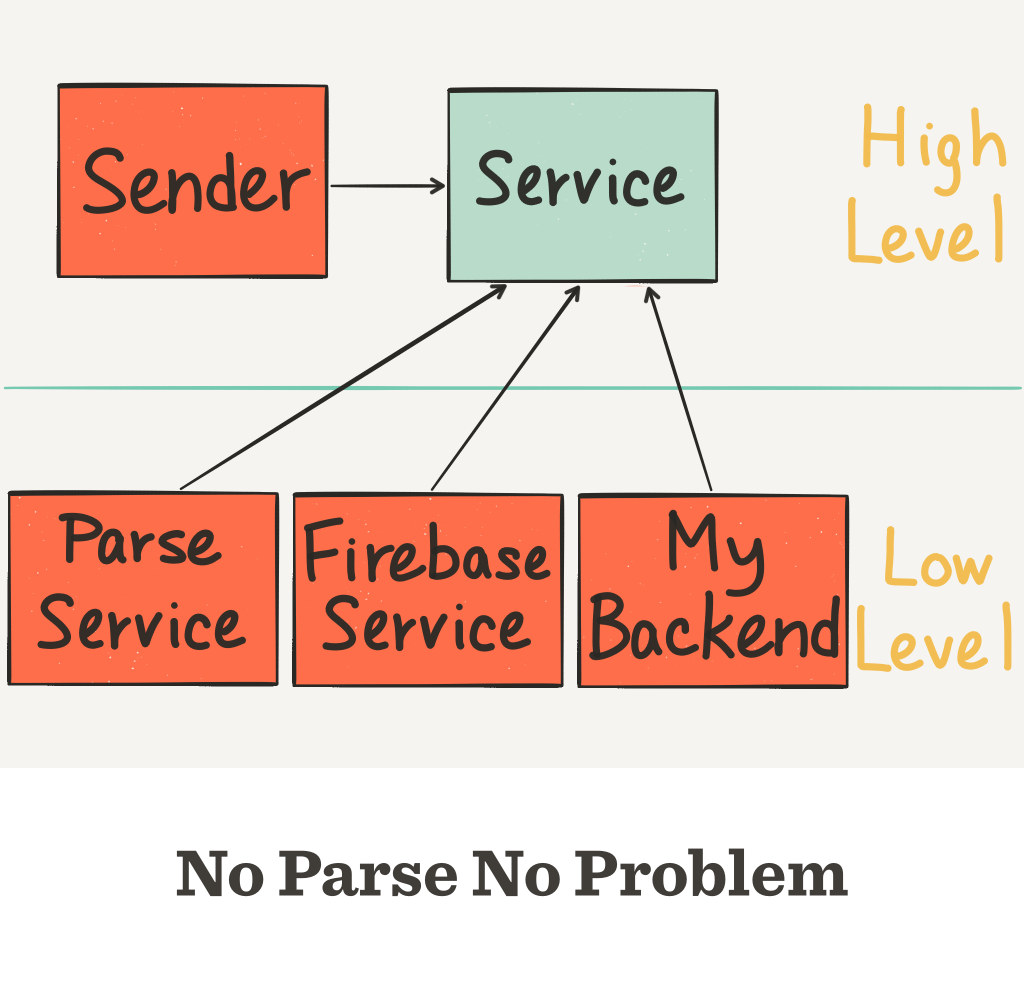
Now, if you need to swap out ParseService with FirebaseService, you only need to supply an instance of FirebaseService when you create the Sender:
|
1 2 3 |
let firebaseService = FirebaseService() let sender = Sender(firebaseService) |
And provide a specific implementation for FirebaseService.
Since we also map PFObject to User inside ParseService, PFObject doesn’t spill outside of ParseService. The rest of your code base doesn’t need to change at all. You just need to do another similar mapping from FDataSnapshot to User inside FirebaseService.
This is a HUGE benefit provided by the Dependency Inversion Principle. When dependencies are isolated from one another by the use of a protocol interface abstraction, making changes becomes just swapping in another plugin.
What makes dependency inversion possible?
Polymorphism.
Polymorphism is a language feature that facilitates the inversion of dependencies. It allows us to specify a variable to be of an abstract (protocol) type, instead of a concrete (class) type.
At run time, this variable will be an instance of a concrete class that conforms to the protocol. However, at compile time, the compiler doesn’t need to know the concrete type yet.
At run time, the higher level Sender still depends on the lower level SpecificReceiver. However, at compile time, both the Sender and SpecificReceiver depend on the same Receiver protocol. Therefore, the Dependency Inversion Principle inverts the source code dependency only, while the run time dependency remains from high level to low level.
This is okay. The machine is much more efficient and less error prone than human. The machine can handle any dependency graph and will not get confused. However, developers are human. The inversion of source code dependency helps us design better software applications. It allows us to make changes much easier. It also makes dependency injection possible when we write unit tests.
More code
Let’s continue the translation for the rest of Uncle Bob’s Java code into Swift.
BusinessRule.swift
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
protocol BusinessRuleGateway { func getSomething(id: String) -> Something func startTransaction() func saveSomething(thing: Something) func endTransaction() } class BusinessRule { private var gateway: BusinessRuleGateway init(gateway: BusinessRuleGateway) { self.gateway = gateway } func execute(id: String) { gateway.startTransaction() let thing = gateway.getSomething(id) thing.makeChanges() gateway.saveSomething(thing) gateway.endTransaction() } } |
First, it defines the BusinessRuleGateway protocol. A concrete class that conforms to this protocol must implement the following four methods:
getSomething(_:)startTransaction()saveSomething(_:)endTransaction()
The BusinessRule class defines a private gateway variable of type BusinessRuleGateway. The initializer also accepts a BusinessRuleGateway object used to set this variable. Again, constructor dependency injection is at work here.
The execute(:_) method contains the business logic. Imagine this is a banking app. You first invoke the startTransaction() method to make sure the following code is thread safe. You then ask the gateway to return a Something instance, so that you can invoke makeChanges() which may be a deposit, withdrawal, or transfer operation on a checking account. You’ll also want to save the thing back to the gateway. Think a database save here. Finally, you invoke endTransaction() to commit your changes.
MySqlBusinessRuleGateway.swift
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
class MySqlBusinessRuleGateway: BusinessRuleGateway { func getSomething(id: String) -> Something { // use MySql to get a thing. let thing = Something() return thing } func startTransaction() { // start MySql transaction } func saveSomething(thing: Something) { // save thing in MySql } func endTransaction() { // end MySql transaction } } |
The MySqlBusinessRuleGateway class conforms to the BusinessRuleGateway protocol by implementing the getSomething(_:), startTransaction(), saveSomething(_:), and endTransaction() methods. The details of the implementation is specific to a MySQL database.
You can create more specific implementations such as PostgreBusinessRuleGateway, CoreDataBusinessRuleGateway, BusinessRuleGatewayAPI.
Something.swift
|
1 2 3 4 5 6 7 8 |
class Something { func makeChanges() { // ... } } |
The Something class is just some business logic model. Using the same banking app analogy, Something can be a CheckingAccount or SavingsAccount. The makeChanges() method can be a deposit() or withdraw() method.
What other benefits does the Dependency Inversion Principle provide?
You probably already know you should isolate dependencies as much as possible. But why? If it doesn’t actually benefit me, why would I care?
And you already saw the most important benefit of the Dependency Inversion Principle. Wanna see more?
With the protocol interface abstraction layer, you can swap out ParseService and swap in FirebaseService or MyBackend. This also means you can swap in TestService to run your unit tests.
Why do you want to do that? Because your tests will run much faster. They are lightweight. They don’t need to talk over the network. They don’t depend on the uptime of Parse, Firebase, or your backend. When these external services are down, you can still run your tests. If you are doing TDD, development doesn’t need to stop.
Developing and testing specific implementation of the Service protocol can be completely isolated and delegated to one team of developers. Other developers can work on the high level business logic and the UI. The Service protocol is a contract that is agreed upon. As long as the developers on both sides do not break this contract, things should just work when it comes to integrate.
An excellent post! and it also helped me appreciate its need in TDD while mocking up input/output layers.
Hi Akash,
Yes, dependency inversion is the key to clean architecture, which is key to writing testable code. The input and output protocols make it explicitly clear what boundary methods you need to test. The private methods are free to change as long as the behaviors observed at the boundaries stay intact.
You are right about not learning these things in school. I really appreciate the time you are spending on this. Now i have a clearer understanding of why you coded the VIP the way you did. I didnt even know there was a name for it; Dependency Inversion. Much thanks.
The only thing I have to get used to now is TDD. I’m still finding it slower for me to write up tests, then write the code. Normally i can write up logic just fine with little error without writing the tests first. But that being said, i know some people who swear by TDD. So i’m still getting used to it. I may have to re-read your TDD posts.
Hi Jay,
When D.I. is mentioned, people think of dependency injection, especially constructor dependency injection (there are other kinds). I think this phenomenon is a result of the popularized TDD practice.
I believe dependency inversion comes before dependency injection. Without applying dependency inversion to an application’s architecture, any dependency injection technique is futile. Practicing the best technique to the wrong thing yields average results at best.
I also view TDD as a technique. It suits some people but not others. Other people are better at writing the logic using dependency inversion first, and then write the tests to verify the correctness. Some projects are also better suited with TDD or vice versa.
Personally, I care more about the results than how one gets there. Just like some people prefer vim and others prefer Textmate or Xcode. Heck, you can even use TextEdit or Notepad to write beautiful code. 🙂
Understood. Makes sense. I wont stress myself over TDD for now, but i will eventually look into it more. Thanks
Isn’t the example with Sender/Receiver just a simple application of the Strategy pattern?
You are correct, it is the Strategy Pattern.
This is the first day I dive into DI, from my understanding after reading this post, we should use generic classes (protocol, abstract class, interface) over concrete classes in all cases. Is that correct?
If so, does it applicable in functional programming?
Hi Alex,
A general rule of thumb is to encapsulate a unit/component by an abstraction layer (such as a protocol/interface), in any programming paradigm.
Hi, Raymond! Thanks for a great article! How this principle is applied, for example, in our app we have many classes like, UserManager, BooksManager, ArticlesManager, OrdersManager and it`s impossible to build them all upon a common abstraction. For example Bookmanager may have methods getBooks(), getBookById() etc, and OrdersManager may have methods getOrders(), endOrder(), acceptOrder() etc. Is it better to violate this principle in such cases? Thank you!
Hi Yera,
It’s totally fine to have the different manager classes that you have. There’s nothing wrong with it.
Hi Raymond,
Nice Article!
I am trying to understand what you mean by “improved” in the Improved dependency inversion diagram.
In the article, you mention that:
“In this improved version, not only is the SpecificReceiver swappable, you can also reuse SpecificReceiver* in a totally different app with different business logic.”
However, SpecificReceiver can easily replaced under the non-improved dependency inversion diagram.
Should SpecificReceiver* be replaced by the Receiver*?
So it reads:
“In this improved version, not only is the SpecificReceiver swappable, you can also reuse Receiver* in a totally different module with different business logic.”